Complete DILR Strategy for CAT 2026
SEO promise: Build a DILR strategy for CAT 2026 around set selection, exit rules, accuracy bands, and a 10-week mixed-practice plan.
Evidence note: Refresh CAT notification details from the official IIM CAT site during the annual update pass. Where this draft uses CAT 2025 or institute criteria, it says so directly. CAT 2025 retained the CAT 2024 pattern of 22 DILR questions across 5 sets in a 40-minute section, with +3 for correct answers, -1 for wrong MCQ answers, and no negative marking on TITA [1], [2].
DILR is not won by solving the hardest set. It is won by refusing the wrong set early enough. The section rewards selection, not heroics. For CAT 2026, build a system that finds the first solvable set, exits traps by time, and treats every mock as a set-selection audit. The numbers explain why: 22 questions across 5 sets in 40 minutes leaves 8 minutes per set, before any reading time [1], [2]. Hero solving — picking a set on instinct and grinding — borrows time from a set you have not yet seen, often the most solvable set on the page.
The first 8 minutes - scan all sets before solving
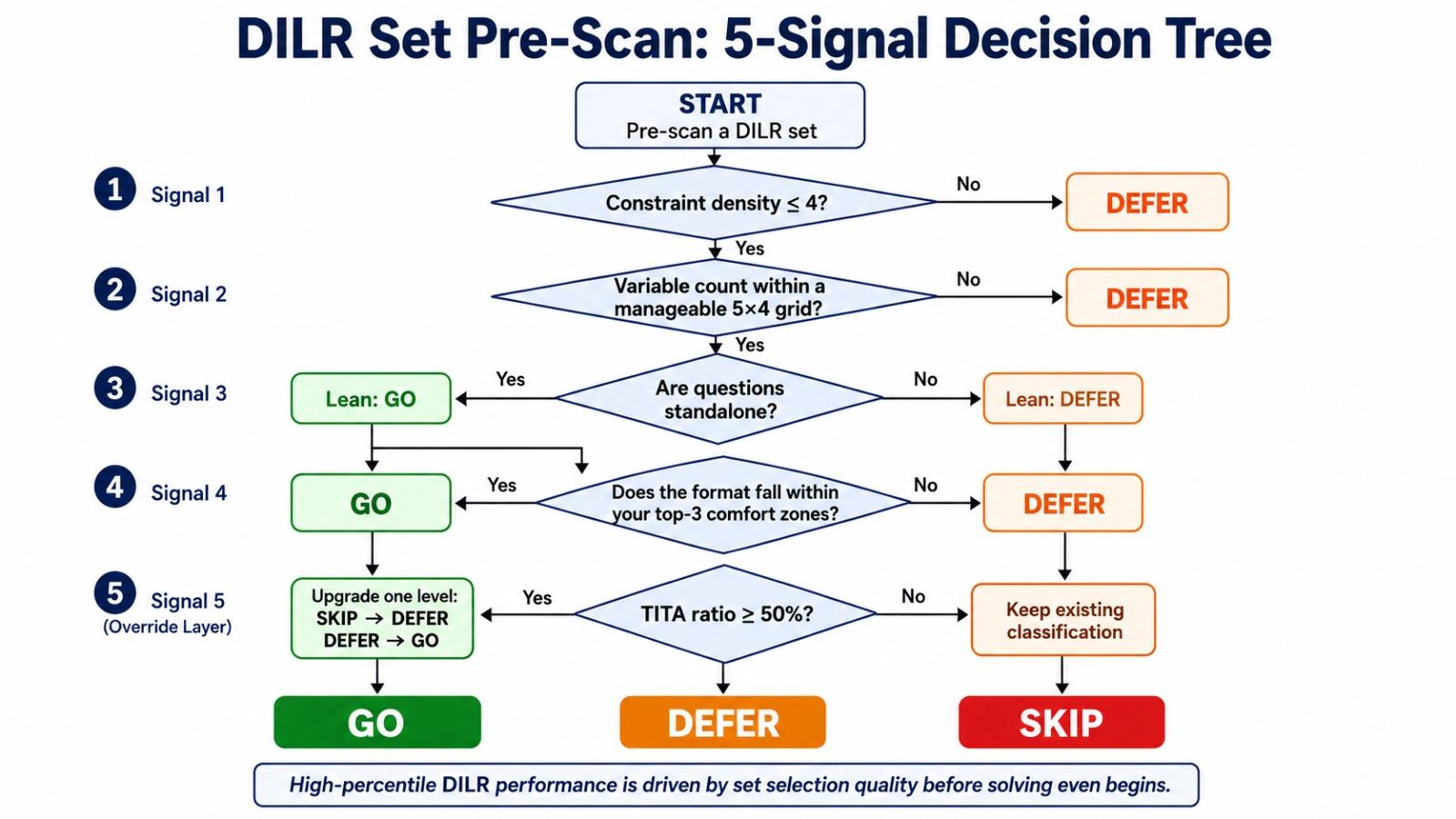
Takeaway: DILR selection should be a deliberate 8-minute investment, not a 40-minute accident.
In the first 8 minutes, read every set title, data structure, number of variables, and question stem. Classify each set as Go, Defer, or Skip. Go sets have clear variables and at least two direct questions. Defer sets look solvable but calculation-heavy. Skip sets have ambiguous constraints or a high setup burden for your current level.
The scan is reading for triage, not comprehension. For each of the five sets, note three things on the rough sheet: data type (table, network, schedule, payoff matrix, free text), number of unknowns to fix (3–4 is comfortable; 6+ is heavy), and question mix (MCQs are recoverable; TITAs with no options are not). A set with 3 unknowns, a clean table, and two MCQs goes to the top of the queue. A set with 6 unknowns, free-text constraints, and four TITAs goes to the bottom.
The scan also surfaces hybrid sets, where DI and LR overlap inside the same caselet. Hybrid sets reward the scan disproportionately — their question mix often splits between trivial extractions and interlocked questions that demand the full setup. If you spot two direct extraction questions inside a hybrid set, they are often worth more than a full third set attempted under time pressure.
Treat the 8-minute scan as fixed cost. Most students who finish with 2 sets cleared instead of 3 lost the third in the first 8 minutes — not the last 13.
Section anchor: 8 minutes for scan.
Set-type recognition - 6 families in 60 seconds
Takeaway: Pattern recognition compresses the scan. Most CAT DILR sets fall into 6 families, and the telltale signal is visible before you read the constraints.

Across CAT 2021–2024 papers, DILR sets cluster into six recurring families [2], [3]. Learn the visual signature of each family during practice, and the scan shifts from "what is this asking" to "I have seen the shape of this before". The table below is a recognition card, not a topic list.
| Set family | Telltale signal in 5 seconds | Typical solve mode |
|---|---|---|
| Linear arrangement | A row of slots or a left-to-right order with ranking constraints | Position chart with fixed and floating elements |
| Circular arrangement | Round-table phrasing, opposite or adjacent conditions | Circular diagram with anchored seat |
| Grid distribution | Rows × columns matrix with partial entries and totals | Fill-by-subtraction across row and column sums |
| Network or routing | Nodes, edges, costs, or shortest-path language | Edge list with cost annotations |
| Games with payoff | Tournament, scoring, points, win-loss table | Result matrix derived from rules |
| Hybrid DI + LR caselet | Free-text scenario with a data table and ordering constraints | Two-stage solve — extract data, then layer constraints |
The signal in the second column is what you see in the first 5 seconds. Circular arrangements announce themselves with phrases like "round table" or "opposite". Grid distributions show up as a half-filled matrix with row or column sums. Networks show edges or routes. Games show a payoff or points column. Hybrid caselets are the slowest to classify — they look like DI but reveal LR constraints once you start reading.
Why six families and not fifteen? Coaching banks subdivide further — Selection and Distribution, Games and Tournaments, Routes and Networks, Venn Diagrams, Caselets, Mathematical Reasoning [2], [3]. Inside the 8-minute scan, granularity hurts. Six families is short enough to memorise and broad enough to cover most slots. The card pays back twice: during the scan it shaves classification time; during post-mock review it lets you tag every failed set by family — if 4 of your last 6 routing sets failed, the repair drill is family-specific.
Section anchor: 6 families.
The 13-minute exit rule - cap a set before it eats the section
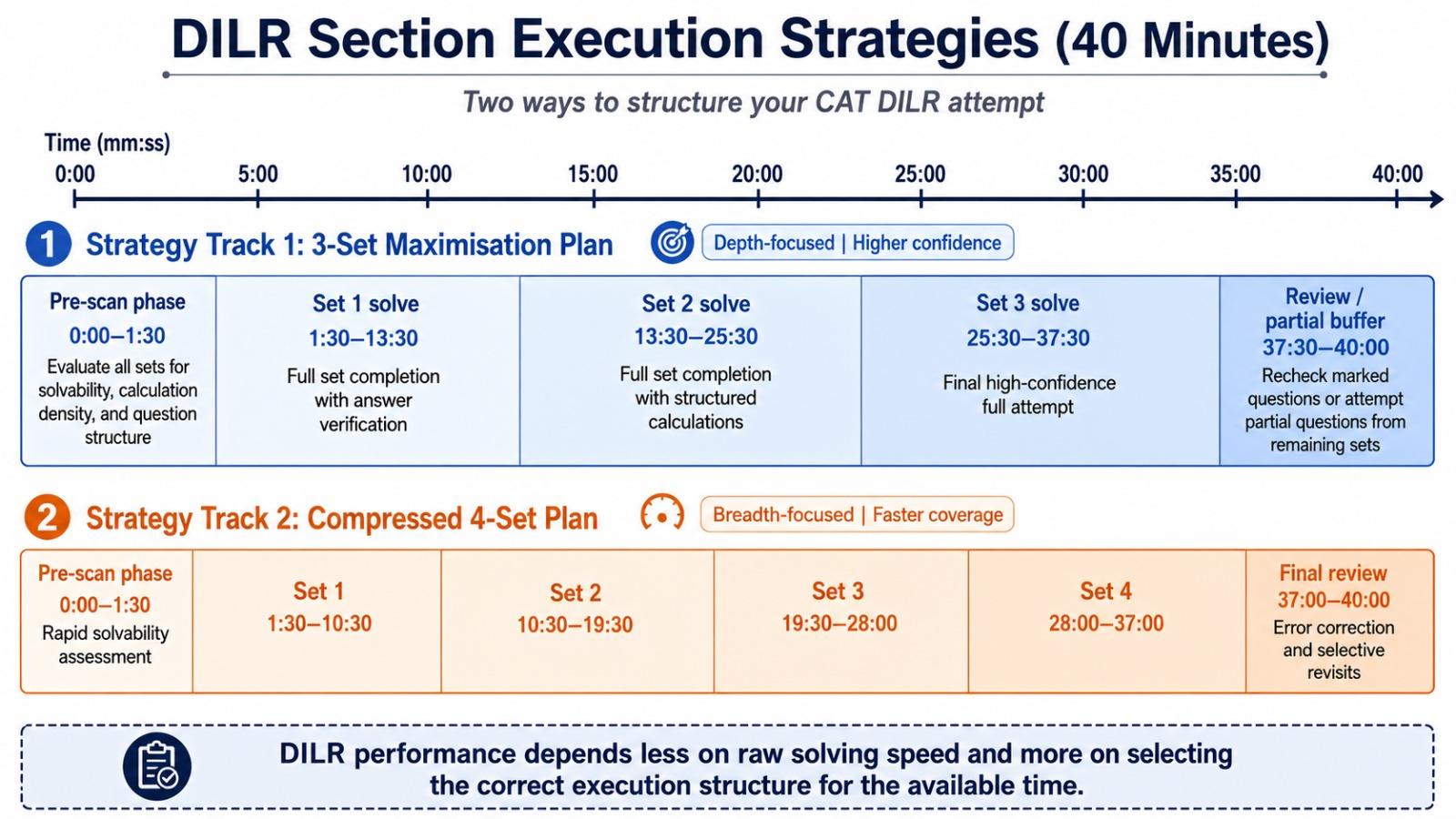
Takeaway: If a set does not produce progress by minute 13, exit with dignity.
A set should show visible progress within 6 minutes and answer production by 10–13 minutes. If the table is still unstable, move. This is not a confidence problem; it is time allocation. A 40-minute section cannot carry one 22-minute failed set.
The 13-minute cap is not arbitrary. With 8 minutes for the scan and a target of 3 cleared sets, the remaining 32 minutes have to host all the solving — 10.7 minutes per set on average. The 13-minute cap gives one set a small overrun while still leaving room for two more. Push past 13 and the section budget collapses.
Exit cleanly. Three steps: mark the questions you can already answer (a partial table often unlocks one or two), commit those answers, then close the set in your head and move to the next Go set. Do not park a set with a vague intention to return — returns force a re-read from scratch.
Diagnostic from your own data: track the longest single-set duration across 5 mocks. If your worst minute is above 18 in any of them, the exit rule is the highest-yield fix in your prep. Most students cut 4 to 6 net marks per mock by capping their worst set at 13 minutes.
Section anchor: 13-minute maximum per first attempt.
Worked caselet walkthrough - selection, setup, solve, check
Takeaway: Strategy sticks when you watch it operate on a set. Below is an example caselet — invented for illustration, not from any official CAT paper — showing scan, setup, partial solve, and answer check.
Example caselet — Five products, four stores. A retailer stocks five products (P1–P5) across four stores (S1–S4). Two constraints: (1) no store carries fewer than 3 units of any product it stocks; (2) S2 stock of P5 equals S3 stock of P2.
| Product | S1 | S2 | S3 | S4 | Total |
|---|---|---|---|---|---|
| P1 | 12 | ? | 8 | 10 | 40 |
| P2 | ? | 6 | ? | 4 | 25 |
| P3 | 5 | 5 | 5 | ? | 20 |
| P4 | ? | 8 | 6 | ? | 28 |
| P5 | 3 | ? | ? | 7 | 22 |
| Total | 35 | 38 | 31 | 31 | 135 |
Step 1 — pre-attempt scan (15 seconds). Grid distribution, 5×4, all numeric, row and column sums given. Constraint 1 is a floor — a one-step verification after the grid is filled. Constraint 2 is a single equation. Two cells fall out by direct subtraction (P1 S2 = 40 − 12 − 8 − 10 = 10; P3 S4 = 20 − 5 − 5 − 5 = 5). This is a Go set.
Step 2 — mini-table setup (45 seconds). Fill the two direct cells (P1 S2 = 10, P3 S4 = 5) and label the remaining four unknowns in row P2 as a, b; row P4 as c, d; row P5 as e, f.
Row equations: a + b = 15; c + d = 14; e + f = 12. Column equations: a + c = 15 (S1); e = 9 (S2); b + f = 12 (S3). Solving: e = 9, f = 3, b = 9, a = 6, c = 9, d = 5.
Step 3 — solve sub-questions. Filled grid: P2 (6, 6, 9, 4), P4 (9, 8, 6, 5), P5 (3, 9, 3, 7). Constraint 2 check: P5 at S2 = 9 = P2 at S3 = 9. Satisfied.
Q1. Units of P2 at S3? Answer: 9. Q2. Which store carries the most P4? Compare 9, 8, 6, 5 — answer: S1.
Step 4 — answer-check ritual (30 seconds). Verify each row and column sums to its total. Verify constraint 1 (floor of 3 — minimum cell value is 3, satisfied). If any check fails, the error sits in the algebra; redo the substitution chain.
Total time: ~5 minutes for two banked questions; two more sub-questions would extend by 2 to 3 minutes — still inside the 13-minute cap. The lesson is the sequence: scan, identify directly solvable cells, chain substitutions rather than guess, verify against constraints. This is the shape of every clean DILR solve.
Section anchor: Example caselet — Five products, four stores.
Accuracy before set count - 1.5 clean sets beat 2.5 messy sets
Takeaway: The first goal is dependable net score, not maximum attempt count.
Early DILR growth comes from preventing negative marks and failed setups. Use the matrix below as a planning aid, not a ranking guarantee — percentile is set by the cohort each year and DILR difficulty varies across slots [4], [5], [6], [8].
| Sets cleared | Accuracy | Net marks (approx) | Realistic percentile band (estimate) |
|---|---|---|---|
| 2 | 90% | ~22 | 85–92 |
| 3 | 80% | ~30 | 92–97 |
| 3 | 90% | ~33 | 95–99 |
| 4 | 70% | ~32 | 94–98 |
| 4 | 55% | ~24 | 80–90 |
The instructive row is the last one. Attempting 4 sets at 55% accuracy looks ambitious but underperforms a 3-set 80%-accuracy plan, because every wrong MCQ costs −1 and every failed setup eats time that could have funded the answer-check on the sets you actually solved. Aggression at low accuracy is mathematically worse than restraint at high accuracy.
Section anchor: 80%+ accuracy before stretch attempts.
When 3 sets beats 4 sets - accuracy math
Takeaway: With 22 DILR questions across roughly 5–6 sets in recent years, a high-accuracy 3-set plan reliably outscores a low-accuracy 4-set plan.
CAT 2024 and CAT 2025 carried 22 DILR questions across 5 sets — two sets of 5 questions and three sets of 4 questions [1], [2]. Recent years have ranged between 5 and 6 sets and 20 to 24 questions, so the budgeting math holds with small variance [2], [3].
Take a student who clears 3 sets cleanly — 12 questions attempted at 80% accuracy. With most wrong answers clustering on TITAs (no penalty [1], [2]), net marks land near 30 — consistently inside the 95+ percentile band in recent slots [4], [8].
The same student attempting 4 sets at 55% accuracy attempts ~17 questions: 9 correct (+27) and 8 wrong. If 4 wrong are TITAs (no penalty) and 4 are MCQs (−1 each), net marks land near 23 — the 80–90 percentile band, a regression despite covering more sets [4], [8].
The marking scheme is the lever. +3 correct, −1 wrong MCQ, 0 wrong TITA [1], [2] — accuracy compounds because each correct answer is worth three wrong answers in absolute value. Two wrong MCQs cancel one of the additional correct answers a stretch attempt earned. Most stretch attempts are wrong at higher rates than home attempts — that is what makes them stretch — so the marginal correct answer carries a tax most students do not price in.
The honest rule: chase 3 sets at 80%+ accuracy first. Only when you can repeat that across 3 consecutive full mocks should you consider a fourth, and only on slots where the scan flags an unambiguous fourth Go set.
Section anchor: 3 sets at 80% beats 4 sets at 55%.
The 10-week DILR loop - 30 sets by type, then mixed sets
Takeaway: Topic comfort is useful only if it survives mixed selection. The skeleton below is the minimum output; the next section gives per-phase daily and weekly counts.
| Weeks | Focus | Minimum output |
|---|---|---|
| 1-4 | Set types by family | 30 sets |
| 5-7 | Mixed sectionals | 6 sectionals |
| 8-10 | Mocks + review | 8 mock reviews |
Section anchor: 10 weeks, 30 typed sets.
10-week DILR drill plan - phase by phase
Takeaway: The 10-week loop split into four phases gives concrete daily and weekly volume targets, so you stop guessing whether you trained enough.
| Phase | Weeks | Daily set count | Sectionals/week | Mocks/week | Primary focus |
|---|---|---|---|---|---|
| Foundation | 1–3 | 2 sets | 0 | 0 | Family recognition, clean setup discipline |
| Set-type rotation | 4–6 | 3 sets, one per family per day | 1 | 0 | Reach 80% accuracy inside each family |
| Mixed mocks | 7–9 | 2 mixed sets | 2 | 1 | Selection under time, exit-rule enforcement |
| Peak rehearsal | 10 | 1 set + 1 sectional | 2 | 3 | Calibration, not learning |
Foundation (weeks 1–3). Slow practice, no time pressure. Two sets a day from different families. Aim for 100% accuracy with unlimited time, then review which constraint did the heavy work. By week 3, the six families should be visually recognisable within 5 seconds.
Set-type rotation (weeks 4–6). Three sets a day, one each from three different families on rotation. Introduce one 40-minute sectional per week — for scan-and-exit practice, not score chasing. Track which families you defer most; rotation should over-index on those for the next two weeks.
Mixed mocks (weeks 7–9). Two mixed sets daily plus two sectionals and one full CAT mock per week. The full mock is where the 8-minute scan and 13-minute exit rule have to hold. Score is secondary to the post-mock log — every set gets a row.
Peak rehearsal (week 10). Volume drops; calibration rises. One set per day plus one sectional. Three full mocks, ideally on the same weekdays as your CAT slot. The goal is consistency of decision, not new learning.
The table assumes 90 minutes per weekday and 3 hours per weekend day. Compress to 60 minutes per weekday by halving daily set count in foundation and rotation, but do not skip the sectionals or full mocks in weeks 7–10.
Section anchor: Foundation, rotation, mixed, peak.
Review method - classify every failed set into 4 causes

Takeaway: A DILR error log without cause labels becomes a scrapbook.
Use four causes: misread constraint, weak setup, calculation drift, and late exit. The repair task depends on the cause. Misread constraints require underline drills. Weak setup requires template practice. Calculation drift requires unit checks. Late exit requires timer enforcement.
Section anchor: 4 cause labels.
DILR error log - 5 columns every student should track
Takeaway: Five columns turn a vague "I am bad at DILR" into a list of specific repair drills with weekly progress.
Each row is one failed or partially failed set from a sectional or mock.
| Column | What it records | Example entry |
|---|---|---|
| Set type | Which of the six families the set belonged to | Grid distribution |
| Time spent | Minutes consumed on this set | 18 minutes |
| Exit decision | Whether the 13-minute cap was honored | Late exit by 5 minutes |
| Failure cause | One of the four labels | Late exit + weak setup |
| Repair drill | The drill scheduled for this gap | 5 grid-distribution sets, 12-minute cap each |
The first three columns are descriptive; the last two are prescriptive — they convert failure into next week's practice. Without the repair drill column, the log becomes a list of regrets. With it, the log becomes a schedule.
Review the log every Sunday. Count failure causes from the previous week and weight the upcoming week toward the most frequent cause. If late exit shows up in 4 of 7 rows, the headline drill is timer enforcement — a hard alarm at 13 minutes across all weekday practice. The log also doubles as a CAT-readiness summary for mentor reviews — five rows with cause labels diagnose your DILR in 90 seconds where a percentile score cannot.
Section anchor: 5 columns - type, time, exit, cause, drill.
FAQs
How many DILR sets should I attempt?
Train for 2 clean sets first. Stretch attempts should come only after accuracy is stable.
Should I scan all DILR sets?
Yes. The scan prevents commitment to the first visible but unsuitable set.
What is the best DILR practice source?
Use previous CAT papers and high-quality mixed sets. Label coaching analytics as estimates, not official distributions.
Should I use the on-screen calculator for caselets?
The on-screen calculator is available in DILR but most successful attempts use it sparingly. Reach for it on multi-digit multiplications and percentage chains, not on row-and-column subtractions where mental arithmetic is faster than the click.
How do I handle a set I have never seen before?
Force-classify it into the closest of the six families during the scan. If no family fits, defer the set and revisit only if your first two Go sets finish under budget. New families are usually slight twists on grid distribution or hybrid caselets — the underlying setup mechanics still apply.
Is mock DILR easier than CAT DILR?
Slot variance makes the comparison unreliable. Treat mocks as decision rehearsal rather than score prediction; the value sits in the post-mock log [4], [8], not in the raw score.
How many DILR sets per day is enough?
Foundation phase: 2 sets a day. Rotation phase: 3 sets across three families. Mixed-mock phase: 2 mixed sets plus 2 sectionals and 1 full mock per week. More volume without review is wasted reps.
Conclusion
This week, solve 12 DILR sets. For each set, record setup time, first answer time, and whether the exit rule was followed. By the next mock, you need 12 rows, not a vague feeling of improvement.
References
[1] Indian Institutes of Management, "CAT official website," 2025. [Online]. Available: https://iimcat.ac.in/. Accessed: Jun. 15, 2026.
[2] Wikipedia contributors, "Common Admission Test - CAT 2024 and 2025 pattern, DILR question count, marking scheme," 2026. [Online]. Available: https://en.wikipedia.org/wiki/Common_Admission_Test. Accessed: Jun. 15, 2026.
[3] Cracku, "CAT DILR topic-wise weightage and set-type distribution across CAT 2021–2024," 2025. [Online]. Available: https://cracku.in/cat-dilr-topic-wise-weightage/. Accessed: Jun. 15, 2026.
[4] Times of India Education, "CAT 2025 exam pattern and strategy reporting," 2025. [Online]. Available: https://timesofindia.indiatimes.com/education/news. Accessed: Jun. 15, 2026.
[5] 2IIM, "CAT previous-year question papers," 2025. [Online]. Available: https://online.2iim.com/CAT-question-paper/. Accessed: Jun. 15, 2026.
[6] InsideIIM, "CAT preparation and admission analysis," 2025. [Online]. Available: https://insideiim.com/. Accessed: Jun. 15, 2026.
[7] 2IIM, "CAT score calculator and score-vs-percentile estimates," 2025. [Online]. Available: https://online.2iim.com/CAT-score-calculator/. Accessed: Jun. 15, 2026.
[8] Cracku, "CAT score calculator," 2025. [Online]. Available: https://cracku.in/cat-score-calculator/. Accessed: Jun. 15, 2026.
[9] Career Launcher, "CAT marks vs percentile," 2025. [Online]. Available: https://www.careerlauncher.com/cat-mba/cat-marks-vs-percentile/. Accessed: Jun. 15, 2026.
[10] MBAUniverse, "CAT score vs percentile analysis," 2025. [Online]. Available: https://www.mbauniverse.com/articles/cat-score-vs-percentile. Accessed: Jun. 15, 2026.
[11] IMS India, "CAT analysis and preparation resources," 2025. [Online]. Available: https://www.imsindia.com/blog/cat/. Accessed: Jun. 15, 2026.
[12] Career Launcher, "CAT preparation resources," 2025. [Online]. Available: https://www.careerlauncher.com/cat-mba/. Accessed: Jun. 15, 2026.
[13] National Institutional Ranking Framework, Ministry of Education, "India Rankings 2025: Management," 2025. [Online]. Available: https://www.nirfindia.org/Rankings/2025/ManagementRanking.html. Accessed: Jun. 15, 2026.
Related reading
DILR set selection for CAT: choose the set before solving it
CAT Percentile Explained for 2026
Understand CAT percentile as a rank-based measure, why it differs from marks, and why score tables must be treated as year-specific estimates.
The Complete CAT Mock Test Playbook for 2026
Use a 12-week CAT mock-test playbook with mock frequency, 48-hour postmortems, section repair, and score-table caveats.
CAT Composite Score Explained for 2026
Understand how IIMs combine CAT score with profile factors, using IIM Ahmedabad’s official shortlist formula as the worked example.