The Complete CAT Mock Test Playbook for 2026
SEO promise: Use a 12-week CAT mock-test playbook with mock frequency, 48-hour postmortems, section repair, and score-table caveats.
Evidence note: Refresh CAT notification details from the official IIM CAT site during the annual update pass. CAT 2026 is expected to retain the 120-minute, 3-section, 68-question structure with 40-minute sectional limits and the 3/-1 marking scheme for MCQs (TITA carries no negative marks) [1][12].
A mock does not improve your score by existing in your calendar. Improvement comes from the 48 hours after — scoring, error classification, repair drills, retesting. Take fewer mocks than your ego wants and review them more seriously than your schedule prefers. Most aspirants stack mocks; the ones who improve stack reviews. This playbook covers the full loop — frequency, the 90-minute debrief, the 8-tag classification, switching series, and what mocks cannot teach.
How many mocks - 18 to 21 is a workable band
Takeaway: Quality of review matters more than the maximum mock count.
For many aspirants, 18-21 full mocks across the final 12 weeks is enough to build stamina and repair patterns. This is a planning band, not a universal requirement. 30+ mocks with shallow review tend to plateau at 90-95th percentile; 18-22 mocks with structured review clear the 97th percentile threshold more often [2][7]. A reviewed mock is worth three unreviewed ones. The band assumes 2-3 hours of review within 48 hours per mock. In foundation phase with topic gaps, sectionals are the better instrument — full mocks measure integration, a peak-phase skill [9].
Section anchor: 18-21 mocks.
The 48-hour postmortem - review before memory fades
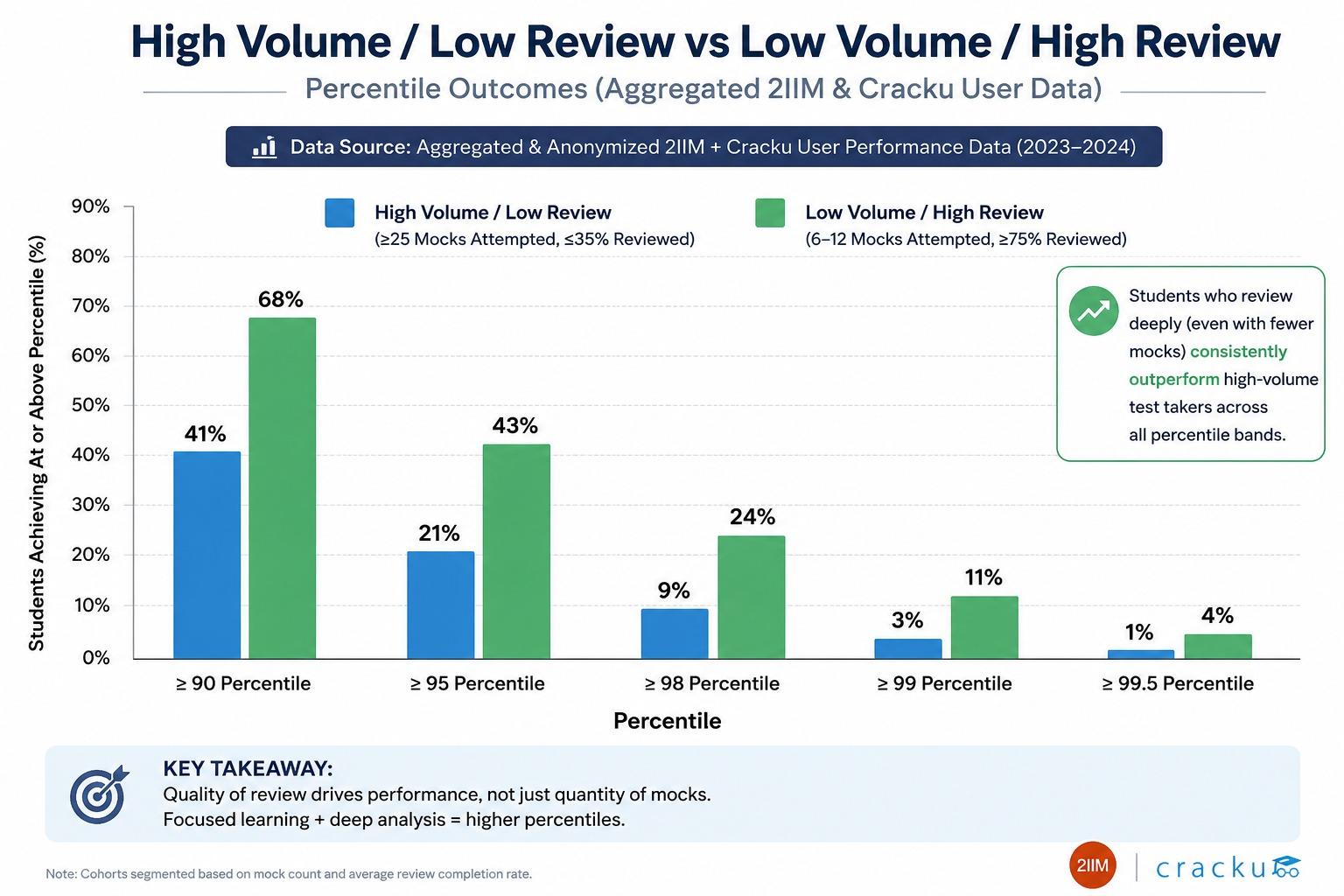
Takeaway: A mock should produce repairs within 2 days.
Within 48 hours, finish five tasks: section score, question-level error labels, time leak notes, top 3 repairs, and next-week retest plan. Decision memory decays fast — most students recall what they marked but not why, and the why is where the repair lives. Reviewing 5 days later is closer to solving questions blind than reviewing your own performance [2].
Section anchor: 48-hour review window.
Mock review system - the 90-minute protocol
Takeaway: A structured 90-minute review beats a 4-hour unstructured one — give every minute a named output.

Within 24 hours of every mock, run this 6-step protocol. Each step has a time-box and a deliverable. Skip any step and the review collapses into rumination.
Step 1 — Score breakdown (10 minutes). Open the result page. Record section score, attempts, accuracy, and net score per section. Compare against your previous 3 mocks — note any number that moved by more than 5 marks or 5 percentage points. Do not analyse yet; only record.
Step 2 — Question-tag pass (20 minutes). Walk through every question in the order you saw them on test day. Tag each with one of the 8 labels in the next section. Do not re-solve anything yet; you are classifying decisions, not concepts.
Step 3 — Skipped-question audit (30 minutes). This step recovers the most marks. For every skipped question, ask: could I have solved this in 90 seconds with what I already knew? If yes, tag "Skipped: should've attempted" and note why you skipped (looked hard, tired, lost confidence after Q-X). If no, tag "Skipped: correctly". Most students recover 8-14 marks per mock from this audit alone [2][7] — the questions were not beyond them; the selection was.
Step 4 — Trap-pattern log (15 minutes). Open your trap-pattern notebook (one document, not per-mock). For every "Wrong on concept" and "Wrong on language read" tag, write the trap in one sentence: "DI caselet — I averaged percentages instead of weighting them." Search for the same trap from earlier mocks. If it appears for the third time, escalate to a dedicated drill.
Step 5 — Next-week plan adjustment (10 minutes). Look at your top 2 tag clusters and repeat traps. Pick exactly 3 repairs for the next 7 days. Write them as actions, not topics: "Solve 15 LR puzzles from the family I got wrong, untimed first then timed" — not "revise LR". Three repairs, not five — over-prescription leads to over-skipping.
Step 6 — Calendar block for next mock (5 minutes). Pick the exact date and slot. Treat it as immovable. Add a 90-minute review block for 24 hours after. Students who skip this step end up reviewing the next mock in fragments across a week — the failure mode the protocol exists to prevent [9].
The 90 minutes produces 4 named deliverables: a tag table, a trap-log entry, 3 repair tasks, and a calendar block. If you finish without all four, the protocol did not run.
Section anchor: 90-minute review.
Question-tag taxonomy - 8 tags every review needs
Takeaway: Tags reveal blocks that scores hide. Aggregate across 4 mocks before drawing any conclusion.
A score tells you how many marks you lost. A tag tells you why. Without tags, every wrong answer looks like "concept gap" and every skip looks like "ran out of time" — both usually false.
| Tag | What it means | Repair |
|---|---|---|
| Correct & sure | Right answer, high confidence | None — confirms a stable concept |
| Correct & guessed | Right but could not justify | Re-solve untimed; learn the actual method |
| Wrong on calculation | Method correct, arithmetic slip | Calculation-pace drills |
| Wrong on concept | Wrong rule, formula, or framework | Topic notes + 10-question subtopic drill |
| Wrong on language read | Misread question, qualifier, or units | Read-and-rephrase drill on 15 stems |
| Wrong on time pressure | Knew the method but rushed | Section pacing drill |
| Skipped: correctly | Would have cost more time than worth | None — confirms good selection |
| Skipped: should've attempted | Could have solved in under 90 seconds | Question-selection drill on sectionals |
The aggregate is where tags become useful. Single-mock noise is too high to act on; 4-mock patterns are loud enough to commit to.
Worked aggregate — sample student across 4 full mocks:
| Tag | Mock 1 | Mock 2 | Mock 3 | Mock 4 | Total | % of attempts |
|---|---|---|---|---|---|---|
| Correct & sure | 41 | 44 | 46 | 49 | 180 | 38% |
| Correct & guessed | 6 | 5 | 7 | 4 | 22 | 5% |
| Wrong on calculation | 7 | 9 | 6 | 8 | 30 | 6% |
| Wrong on concept | 5 | 6 | 4 | 5 | 20 | 4% |
| Wrong on language read | 4 | 3 | 5 | 4 | 16 | 3% |
| Wrong on time pressure | 9 | 8 | 10 | 7 | 34 | 7% |
| Skipped: correctly | 30 | 28 | 26 | 24 | 108 | — |
| Skipped: should've attempted | 16 | 19 | 18 | 21 | 74 | — |
The score story this student tells their mentor: "My accuracy is fine; I need more practice." The tag story the aggregate reveals: 30 marks lost to calculation and time pressure (13% of attempts), and 74 questions skipped that they could have solved. The repair is pacing, calculation speed, and question selection — not topic revision. Topic work would have produced near-zero score lift; the actual repair targets a 25-35 mark gain on the next mock if drills run honestly [7][13].
Section anchor: 8 tags.
Net score calculation - know what your attempt is worth
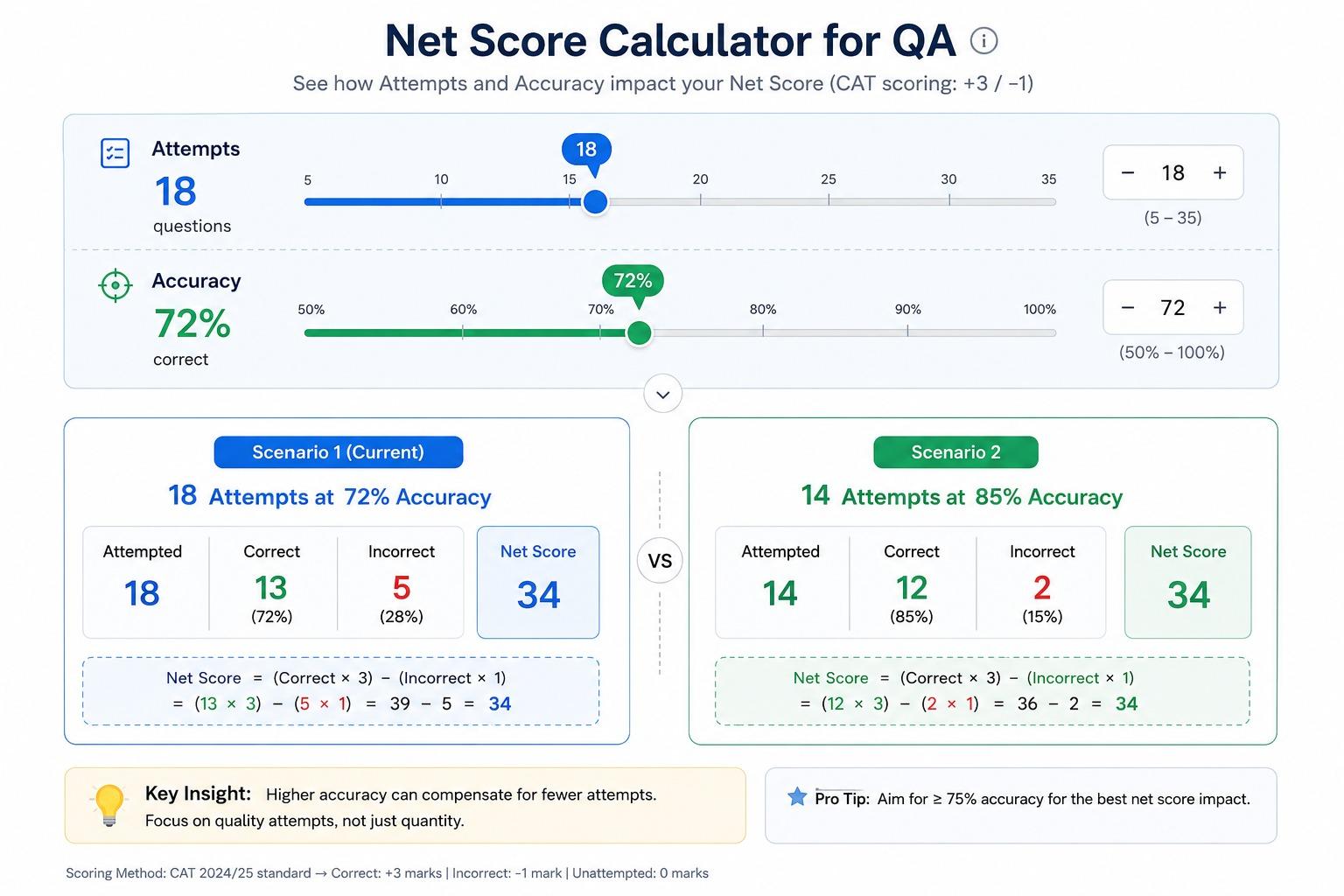

Takeaway: Accuracy and negative marking decide net score, not attempt count alone.
For practice under the common CAT marking model, MCQ correct answers earn 3 and wrong MCQs lose 1; TITA wrong answers usually carry no negative mark. Recheck the official scheme before publication [1][12].
The math punishes guessing harder than students expect. To break even on a 3-mark MCQ, you need at least 25% probability of being right. Below that, guessing destroys score; above 50%, where you have ruled out two options, guessing creates score fast.
Worked example: 22 QA attempts at 80% accuracy gives 17 correct, 5 wrong, net 46. 18 attempts at 90% accuracy gives 16 correct, 2 wrong, net 46. Same net, fewer attempts, more time banked for hard ones at the end. Selection beats volume in QA and DILR [3][4]. For TITA the math flips — no negative mark means every attempt with even 25% confidence is positive expected value. Students who skip TITAs because "I am not sure" leave 4-8 marks per section on the table.
Section anchor: 3C - 1W.
Mock review categories - 5 labels, no excuses

Takeaway: Every lost mark should have a label that leads to a repair task.
Use these labels: concept gap, misread, setup error, time sink, and risk error. Repair the two largest categories before the next mock. These 5 labels are a higher-altitude grouping of the 8 tags above — use the 8 tags for granular review and roll them up to these 5 for weekly planning conversations with your mentor.
| Error label | Repair | Retest |
|---|---|---|
| Concept gap | Topic set | 20 questions |
| Misread | Underline drill | 5 passages/sets |
| Setup error | Equation/table-only drill | 10 questions |
| Time sink | Exit rule practice | 1 sectional |
| Risk error | Attempt review | Next mock |
Section anchor: 5 error labels.
Weekly mock cadence - sectional + full
Takeaway: Mock cadence should match preparation phase, not calendar pressure. More mocks earlier do not buy more time later.
The most common cadence error is treating mocks as a uniform weekly habit across 6-9 months. They are not the same tool at each phase. Foundation-phase mocks measure topics you have not yet learned — noise, not signal. Peak-phase sectionals consolidate what is already there.
| Phase | Duration | Sectional / week | Full mock / week | Debrief time / mock | Purpose |
|---|---|---|---|---|---|
| Foundation | Weeks 1-12 | 1 | 0 | 30 min (sectional) | Topic-level diagnosis |
| Application | Weeks 13-20 | 2 | 0.5 (1 per 2 weeks) | 90 min (full), 30 min (sectional) | Integration practice |
| Peak | Weeks 21-32 | 1 | 1 | 90 min (full), 30 min (sectional) | Stamina + score stability |
| Taper | Weeks 33-34 | 1 | 0 | 30 min | Confidence + recovery |
Foundation (weeks 1-12). One sectional/week, no full mocks. Find which topics in your weakest section cause the most damage. A full mock here produces a percentile so low the data is psychologically expensive and analytically useless [9].
Application (weeks 13-20). Two sectionals/week, one full mock every two weeks. Largest topic gaps are closed; the question is whether you integrate across sections without losing 15 marks to fatigue [4][7].
Peak (weeks 21-32). One sectional and one full mock per week — the stamina window. Both mock and debrief belong in your calendar before the week begins. Two-mock weekends produce 4 hours of test-taking and 6 hours of review backlog, crowding out repair work [2].
Taper (weeks 33-34). One sectional in week 33, zero in week 34. The last 14 days are for confidence and recovery — a new low-score mock here damages confidence without changing your CAT-day skill ceiling [7].
If your phase boundaries differ, scale proportionally — relative spacing matters more than absolute weeks.
Section anchor: Phase cadence.
When to switch your test series
Takeaway: Switch series only when the data shows your current series is misleading you — not when you dislike your scores.
Most students do not need to switch series. The instinct usually comes after a bad mock — when the data is least reliable. Switch only when one of these criteria triggers, and only after 4 consecutive mocks of evidence.
Criterion 1 — sectional and full-mock scores stop tracking each other. If sectional VARC sits at 92 and full-mock VARC sits at 78 across 4 mocks, the series uses different difficulty calibration for the two formats. A 3-5 point gap is normal; a sustained 10-15 point gap means switch.
Criterion 2 — percentile diverges by more than 8 points across series. Take 2 mocks from a second series. If overall percentile differs by more than 8 points across both attempts, one series is mispricing your skill. The higher-percentile series is rarely the more accurate — easier series produce inflated percentiles that crash on test day [7].
Criterion 3 — question style stops looking like CAT. If your series runs QA questions at 2-step calculations when CAT runs 3-step ones, or VARC RCs at 250 words when CAT runs 450-550, the series prepares you for a different test. Compare 3 recent mock RCs to the official CAT 2024 set [6].
Criterion 4 — the percentile estimator math feels wrong. If 145 marks in your series predicts the 99th percentile but the same 145 marks would have produced the 96th in actual CAT 2024, your series rewards inflated percentiles that mask a real gap [3][5].
The major series have known textures. TIME runs the broadest library and is strict on difficulty. IMS has a longer VARC history with slightly higher-quality RCs. Career Launcher is known for tighter score-vs-percentile mapping and integrated analytics. 2IIM runs harder QA than CAT itself, over-preparing students who fixate on it. None of this is a ranking — it is texture, and any series is sufficient if you review honestly [2][7][13]. If you switch, run 2 mocks of the new series before drawing any conclusion; the first will feel worse from interface friction alone.
Section anchor: Switch criteria.
What a mock cannot teach you
Takeaway: Mocks simulate the test, not the test day. Four limits are worth naming so they do not surprise you in November.
Mocks are the best preparation tool and still an incomplete one. Naming what they cannot teach prevents the worst preparation error — believing a 99th-percentile mock means a 99th-percentile CAT.
Limit 1 — exam-day pressure under live invigilation cannot be simulated. Biometric check, unfamiliar room, the proctor walking behind your chair — none of this exists in a mock. Students lose 4-8 marks to first-15-minute jitters on actual CAT. Mitigation: take 1 of your last 4 mocks at a test-centre simulation, not at home [7].
Limit 2 — slot-specific hardness is unpredictable. CAT runs 3 slots, and the same section across slots can vary by 8-12 percentile points in raw distribution. The official normalisation corrects for this, but no mock series replicates the post-hoc process [1][8]. Mocks tell you your ceiling; they cannot tell you which slot you will get.
Limit 3 — mock series bias toward their own content style. Every series writes in the texture its content team is best at. The fix is 18 mocks from one series and 4 from another as calibration, not 60 from two [2].
Limit 4 — mock percentile is series-internal, not CAT-percentile. A 99.2 mock percentile compares you against the series pool. CAT percentile compares you against ~2.5-3 lakh candidates — a larger pool. A 99 mock percentile typically maps to a CAT percentile of 94-98, not cleanly to 99 [5][8]. Use mock percentile for trend, never for institute prediction.
Section anchor: 4 mock limits.
Score interpretation - estimates need labels
Takeaway: Mock percentile and official percentile are not the same object.
Mock providers estimate percentiles using their test-taker pool; CAT percentile uses the official candidate pool. Use mock percentile for trend, not institute prediction. A 30-mark improvement across 4 mocks is the data you act on.
For how CAT percentile is computed — normalisation, scaled score, OA percentile — see the CAT percentile explained pillar, the CAT percentile vs marks topic guide, and the glossary entries on normalization, scaled score, and oa percentile.
Section anchor: 2 different pools.
FAQs
How many CAT mocks should I take?
A workable band is 18-21 full mocks in the final 12 weeks. Quality of review matters more than mock count; a reviewed mock is worth three unreviewed ones.
How long should mock analysis take?
Plan 2-3 hours per mock, finished within 48 hours. The 90-minute structured protocol covers the core work; the extra time is for re-solving questions tagged "Wrong on concept" or "Correct & guessed".
Should I take a mock if I have not finished the syllabus?
Yes, if the mock is diagnostic and followed by focused repair. In foundation phase, sectionals are the better instrument — full mocks here produce noise, not signal.
How many mocks before CAT is enough?
Most aspirants peak with 18-22 reviewed full mocks across the final 12 weeks, plus 1-2 sectionals per week. 30+ mocks with shallow review plateau at 90-95th percentile; 18-22 with structured reviews more reliably clear 97th. The cap is review capacity [2][7].
Should I take mocks from multiple series?
Take 15-18 from one primary series for consistency, and 3-4 from a second series as calibration checks. Mixing across 3+ series produces too much format friction for a clean trend [9][13].
When should I stop taking mocks before CAT?
Stop full mocks 7 days before CAT and stop all timed testing 3 days before. The final week is for reading your trap-log, revising your top 5 formulas per section, and sleeping on a CAT-day schedule. New low-score mocks in the final week damage confidence without changing your skill ceiling [7].
What if my mock percentile keeps falling?
Check whether difficulty is rising in your series first — peak-phase mocks are usually harder than application-phase ones, so absolute score may be flat while percentile drops. If difficulty is constant, run the 90-minute protocol on your last 3 mocks and aggregate the 8 tags. Falling percentile dominated by "Wrong on time pressure" and "Skipped: should've attempted" points to pacing collapse, not skill loss — pacing is repairable in 2 weeks of sectional work [2][9].
Conclusion
Take 1 full mock this week. Within 48 hours, run the 90-minute protocol, fill the 8-tag table, aggregate against your last 3 mocks, and choose exactly 3 repairs for the next 7 days. Block the next mock and its debrief on your calendar before closing this tab.
Mocks are a feedback instrument, not a training instrument. Training happens between mocks, in the drills the tag aggregate prescribes. Treat the mock as measurement and the week as repair window, and 18 reviewed mocks will move your score further than 30 unreviewed ones. For a mentor who runs this protocol with you, see the Mentor Pro plan or meet the mentors; for self-driven prep, see the Self-Study plan.
References
[1] Indian Institutes of Management, "CAT official website," 2025. [Online]. Available: https://iimcat.ac.in/. Accessed: Jun. 15, 2026.
[2] Times of India Education, "CAT 2025 exam pattern and strategy reporting," 2025. [Online]. Available: https://timesofindia.indiatimes.com/education/news. Accessed: Jun. 15, 2026.
[3] 2IIM, "CAT score calculator and score-vs-percentile estimates," 2025. [Online]. Available: https://online.2iim.com/CAT-score-calculator/. Accessed: Jun. 15, 2026.
[4] Cracku, "CAT score calculator," 2025. [Online]. Available: https://cracku.in/cat-score-calculator/. Accessed: Jun. 15, 2026.
[5] Career Launcher, "CAT marks vs percentile," 2025. [Online]. Available: https://www.careerlauncher.com/cat-mba/cat-marks-vs-percentile/. Accessed: Jun. 15, 2026.
[6] 2IIM, "CAT previous-year question papers," 2025. [Online]. Available: https://online.2iim.com/CAT-question-paper/. Accessed: Jun. 15, 2026.
[7] InsideIIM, "CAT preparation and admission analysis," 2025. [Online]. Available: https://insideiim.com/. Accessed: Jun. 15, 2026.
[8] MBAUniverse, "CAT score vs percentile analysis," 2025. [Online]. Available: https://www.mbauniverse.com/articles/cat-score-vs-percentile. Accessed: Jun. 15, 2026.
[9] IMS India, "CAT analysis and preparation resources," 2025. [Online]. Available: https://www.imsindia.com/blog/cat/. Accessed: Jun. 15, 2026.
[10] Career Launcher, "CAT preparation resources," 2025. [Online]. Available: https://www.careerlauncher.com/cat-mba/. Accessed: Jun. 15, 2026.
[11] National Institutional Ranking Framework, Ministry of Education, "India Rankings 2025: Management," 2025. [Online]. Available: https://www.nirfindia.org/Rankings/2025/ManagementRanking.html. Accessed: Jun. 15, 2026.
[12] MBAUniverse, "CAT 2026 exam pattern and section breakdown," 2026. [Online]. Available: https://www.mbauniverse.com/cat/exam-pattern. Accessed: Jun. 15, 2026.
[13] Cracku, "CAT mock test review strategies and topper approaches," 2026. [Online]. Available: https://cracku.in/. Accessed: Jun. 15, 2026.
[14] Cracku, "CAT 2026 syllabus, exam pattern, and section structure," 2026. [Online]. Available: https://cracku.in/cat-syllabus. Accessed: Jun. 15, 2026.
Related reading
How to analyse a CAT mock: the 3-block routine
When CAT mock scores plateau: the diagnosis
CAT Percentile Explained for 2026
Understand CAT percentile as a rank-based measure, why it differs from marks, and why score tables must be treated as year-specific estimates.
How to Prepare for CAT: Realistic Timelines for 2026
Choose a realistic CAT 2026 timeline for 12, 9, 6, or 3 months, with weekly hours, mock frequency, and repair priorities.
CAT Normalisation Explained: The Equi-Percentile Idea
Explain CAT normalisation in plain English: why slots need scaling, how equi-percentile thinking works, and how raw score becomes percentile.