Complete QA Strategy for CAT 2026
SEO promise: Build a CAT 2026 QA plan that prioritizes arithmetic, algebra, geometry, mixed practice, and mock-review decisions over formula collection.
Evidence note: Refresh CAT notification details from the official IIM CAT site during the annual update pass. Where this draft uses CAT 2025 or institute criteria, it says so directly.
QA preparation fails when it becomes a formula inventory. CAT QA rewards topic recognition, clean setup, option discipline, and exit timing. For CAT 2026, your plan should answer a narrower question: which 14-18 questions can you convert under a 40-minute sectional limit without donating marks to avoidable negatives?
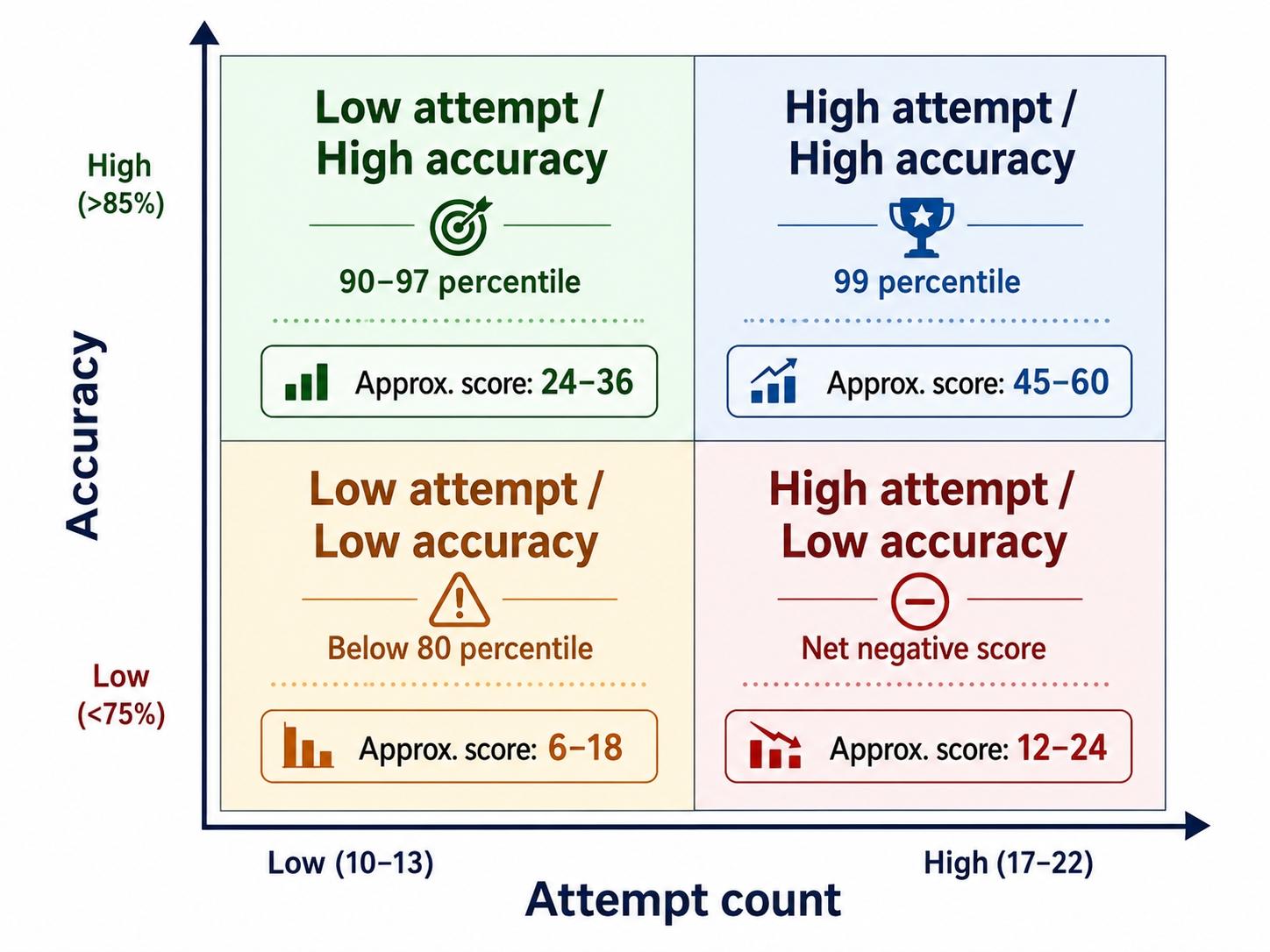
The number that anchors every decision below is 22. That is the QA question count across recent CAT papers, scored at +3 for a correct answer, −1 for a wrong MCQ, and 0 for a wrong TITA [1], [12]. A maximum sectional score of 66 means the difference between a 95-percentile and a 99-percentile attempt is often four to six conversions — not a different syllabus, not a faster brain, but a tighter selection rule and a cleaner setup [5], [6].
What QA actually tests
Takeaway: QA tests recognition under time pressure, not the depth of any one topic.
A CAT QA question rarely asks for an advanced technique. It asks whether you recognise the topic family in the first 20 seconds, set up the correct equation or diagram in the next 40, and execute without arithmetic drift in the remaining 60. The candidates who score in the 95-plus percentile band are not the ones who know the most identities — they are the ones who waste the fewest seconds on questions that were never theirs to convert.
A useful frame: think of the section as a 40-minute auction. You are bidding minutes against an unknown future pool of solvable questions. Every minute you spend on a hard question is a minute you cannot spend later, and you do not yet know how generous or stingy the back half of the paper will be. Conservative bidding — exit at 75 seconds if no entry point appears — is the dominant strategy across mock data published by the major test-prep firms [3], [9].
Section anchor: 22 questions, 40 minutes, recognition first.
QA topic-mix in recent CAT papers
Takeaway: Arithmetic and algebra carry 60 percent of recent QA papers. Build there first.
The exact mix shifts slot-to-slot, but the topic shares have been stable enough that an aspirant can plan around them. The table below pools approximate question counts across the three CAT 2025 slots based on independent analyses from Cracku and 2IIM. These are estimates of historical mix, not an official promise from IIMs [2]. CAT does not publish a topic split, and any single slot can deviate sharply.
| Topic family | Approx. questions per slot (CAT 2025 estimate) | Share of section | Sub-topics that recur |
|---|---|---|---|
| Arithmetic | 6 to 8 | ~32% | Time-Speed-Distance, Time-Work, Profit-Loss, Ratios, Averages, SI/CI |
| Algebra | 6 to 7 | ~30% | Linear and quadratic equations, inequalities, progressions, functions |
| Geometry and Mensuration | 3 to 4 | ~14% | Triangles, circles, coordinate, mensuration of solids |
| Number Theory | 2 to 3 | ~11% | Divisibility, remainders, factorisation, base systems |
| Modern Math | 2 to 3 | ~13% | Logarithms, surds, indices, P&C, probability, set theory |
Source: pooled estimates from Cracku CAT 2025 topic-wise weightage analysis [2] and 2IIM previous-year question paper coverage [3]. Treat as direction, not forecast.
The pattern that matters here is not the absolute count, but the order: any plan that completes geometry before arithmetic spends its scarce early weeks on a topic family that delivers half the question volume. The reverse mistake is equally common — spending week 10 on yet another arithmetic batch when geometry has been ignored since week 4. The roadmap in a later section corrects both errors.
Section anchor: 5 topic families, arithmetic-first ordering.
Topic priority - arithmetic and algebra first

Takeaway: A QA plan should start with high-utility topics before low-frequency comfort topics.
Previous CAT papers and coaching archives are useful for inspecting topic mix, but topic weightage is not an official promise [3]. Start with arithmetic and algebra because they support ratios, percentages, equations, functions, and word problems. Add geometry and modern math after the first layer is stable.
A second filter: prefer topics that re-appear inside other topics. Ratios and percentages re-appear in geometry (similar triangles), in number theory (proportional reasoning), and in modern math (probability). Closing ratios early therefore pays a second dividend three weeks later when you arrive at geometry and find the setup half-built.
Section anchor: 2 Tier-1 topic families.
Time allocation - the 40-minute budget
Takeaway: Reserve the first 8 minutes for sweep-and-mark, the middle 24 for conversion, the final 8 for revisits.
Most aspirants treat the section as 22 sequential decisions. A more honest model is three nested budgets. The first 8 minutes are a screening sweep — read every question once, attempt only the ones that resolve in under 90 seconds, mark the rest with a one-character tag (A for attempt, M for maybe, S for skip). The next 24 minutes work the A and M queue in increasing difficulty order. The final 8 minutes revisit any M or S question with a fresh setup, and audit two earlier answers if the queue is empty.
Why the sweep first? Because the toughest cost in QA is not a wrong answer — it is finishing the paper at question 18 because question 7 ate 6 minutes. A sweep guarantees you have seen every question's surface before any one of them owns your clock. The cost of the sweep is roughly 22 seconds per question; the gain is the option to choose your conversions instead of being chosen by the order they appear.
Section anchor: 8-24-8 minute budget across 22 questions.
Attempt-or-skip protocol - a worked example
Takeaway: The decision to skip is worth more than the decision to attempt. Most QA marks are lost in the second category, not the first.

The clearest way to teach the protocol is on two invented questions. Both are written here as examples — they are not from an official paper.
Example 1 - Clean arithmetic (attempt). A trader buys three identical articles. The first is sold at a 20% profit, the second at a 10% loss, and the third at the cost price. The trader's overall profit on the three articles is Rs. 60. Find the cost price of each article.
Read (5 seconds): profit-loss with three transactions, single unknown, percentages already given. This is a Tier-1 arithmetic problem with a one-line setup.
Setup (15 seconds): Let cost price of each article be . Total cost = . Total revenue = . Net profit = .
Solve (15 seconds): , so .
Audit (10 seconds): 0.10 of 600 is 60. Consistent.
Total time: 45 seconds. This is the question you trained for. Attempt and bank +3.
Example 2 - Quadratic with parameter (skip on first pass). For how many integer values of does the equation have two distinct real roots, both positive integers less than 12?
Read (10 seconds): quadratic in with a parameter , two real-root constraints, both roots are bounded positive integers. The constraints require Vieta's, an integer-search loop, and a bound check at the end.
Setup attempt (20 seconds): Sum of roots = , product of roots = . Both roots positive integers under 12. This is solvable, but it routes through a casework loop and a parameter back-solve.
Decision (instant): This is a 3-to-4-minute conversion at best. Mark M, move on. The expected cost of attempting now is one converted Tier-1 question deferred or lost.
Total time spent: 30 seconds. The cost of moving on is zero marks. The cost of staying would be a probable +3 in 3-4 minutes, traded against two probable +3s elsewhere in 4-5 minutes. Skip wins on expected value.
The general rule: if you cannot describe your solution path in one sentence within 60-75 seconds, mark and move. The penalty for re-entering a marked question on pass 3 is one fresh read. The penalty for forcing it on pass 1 is two unattempted Tier-1 questions later.
Section anchor: 60-75 second skip rule with worked examples.
Negative-marking calculator - when 17 attempts beats 19
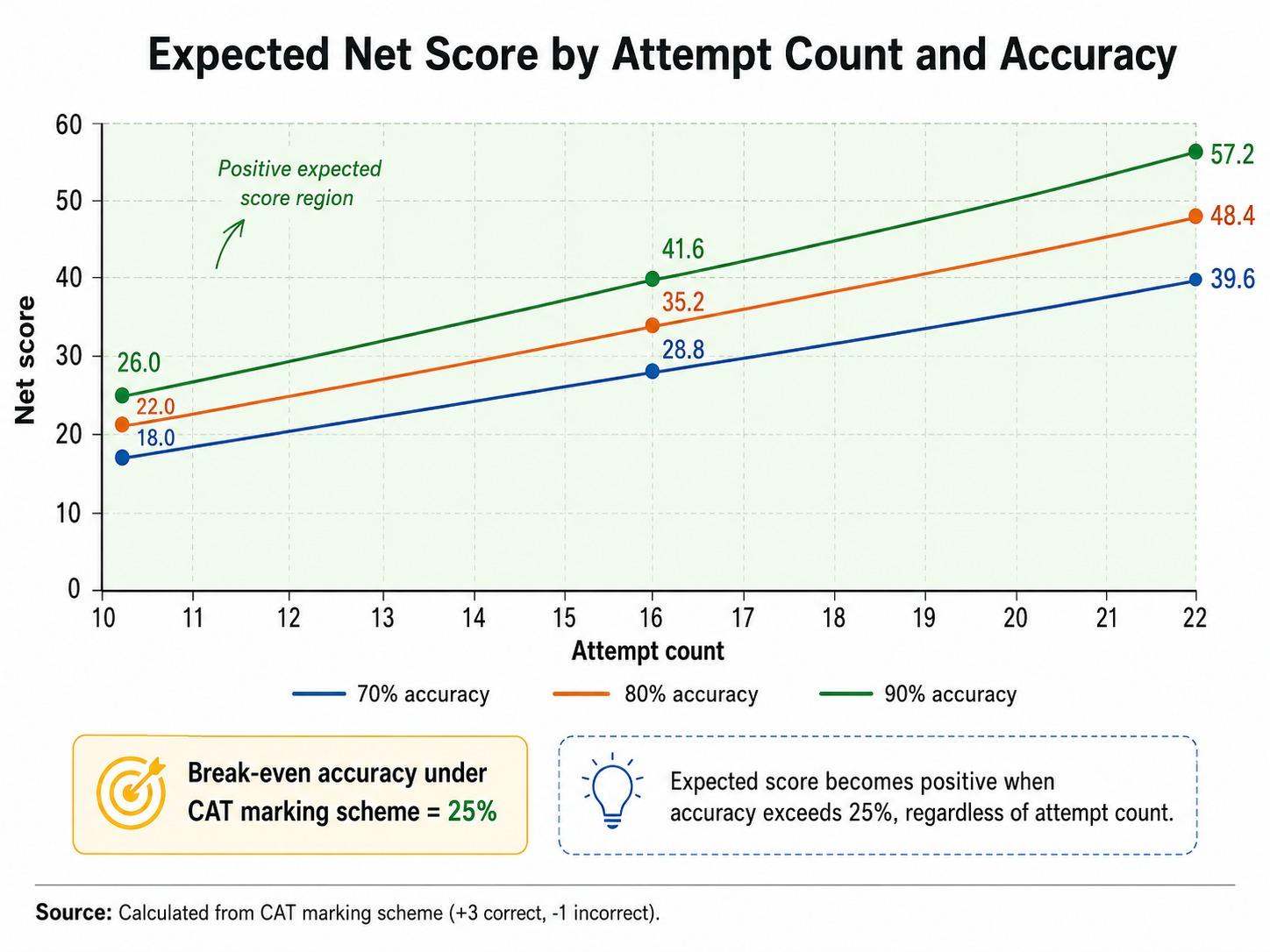
Takeaway: Under CAT's +3/−1 MCQ scheme, accuracy compounds faster than volume. An 82-percent attempt is worth more than a 65-percent attempt at higher count.
The CAT QA marking scheme is +3 for a correct MCQ, −1 for a wrong MCQ, and 0 for a wrong or unattempted TITA [1], [12]. Assume a representative split of 14 MCQs and 8 TITAs in a 22-question paper [3]. The expected score for an attempt set is the sum of (+3 × correct) and (−1 × wrong MCQs).
The table below holds a constant assumption — that aspirants attempt MCQs and TITAs in proportion to the section's mix, so an attempt count of implies roughly MCQs attempted.
| Attempts | Accuracy | MCQs attempted | MCQs correct | MCQs wrong | TITAs attempted | TITAs correct | Net score |
|---|---|---|---|---|---|---|---|
| 19 | 65% | 12 | 8 | 4 | 7 | 5 | |
| 17 | 82% | 11 | 9 | 2 | 6 | 5 | |
| 15 | 90% | 10 | 9 | 1 | 5 | 5 | |
| 22 | 60% | 14 | 8 | 6 | 8 | 6 |
Two observations. First, the 17-attempt/82-percent row beats the 19-attempt/65-percent row by 5 marks. Second, attempting all 22 at 60-percent accuracy underperforms the same 17/82 row by 4 marks. In CAT 2024 score-to-percentile data, a 5-mark swing inside the QA section moves a candidate roughly 3 to 5 percentile points in the 90-95 band [5], [6].
The takeaway is uncomfortable for aspirants who measure progress by attempt count: in QA, attempting fewer with cleaner discipline is the higher-percentile play until accuracy crosses 80 percent. Only after that threshold does pushing the attempt count further become productive.
Section anchor: 82% accuracy threshold before chasing volume.
The 12-week roadmap - learn, mix, then test

Takeaway: A topic is not complete until it survives a mixed timed set.
Weeks 1-3 should build arithmetic. Weeks 4-5 should build algebra. Weeks 6-7 should cover geometry and selected modern math. Weeks 8-9 should switch to mixed timed sets. Weeks 10-12 should be mock-led repair. This order prevents the common trap of knowing formulas but failing topic recognition.
Section anchor: 12 weeks in 5 phases.
12-week QA topic rotation
Takeaway: Time-on-task by phase matters more than time-on-task by topic. Front-load arithmetic; back-load mixed grinds.
The 12-week plan above is the headline view. The version below is the working plan — phase by phase, with hours and drill counts. The hours assume a working aspirant putting in 10-12 QA hours per week; scale proportionally if your weekly cap is different.
Phase 1 — Arithmetic foundation (weeks 1-3). 12 hours/week split as 4 hours concept reading, 6 hours drilling, 2 hours review. Drill target: 60-80 questions per week across Ratios, Percentages, Profit-Loss, SI/CI, Averages, Time-Speed-Distance, Time-Work. Exit criterion: 20 questions correct in a row on a mixed arithmetic set under 60 seconds per question.
Phase 2 — Algebra and Number Theory (weeks 4-6). 11 hours/week split as 3 hours concept, 6 hours drilling, 2 hours review. Drill target: 50-70 questions per week covering Linear and Quadratic equations, Inequalities, Progressions, Functions, Divisibility, Remainders. Exit criterion: solve a quadratic-with-parameter question in under 2 minutes from a clean setup.
Phase 3 — Geometry and Modern Math (weeks 7-9). 10 hours/week split as 3 hours concept, 5 hours drilling, 2 hours review. Drill target: 40-60 questions per week covering Triangles, Circles, Coordinate Geometry, Mensuration, Logarithms, Surds, P&C, Probability. Exit criterion: identify the correct geometric construction for a question in the first 30 seconds, 7 times out of 10.
Phase 4 — Mixed sectional grind (weeks 10-12). 12 hours/week split as 2 hours concept refresh, 8 hours sectional and mock practice, 2 hours review-ledger work. Drill target: 3 full QA sectionals per week, 1 full mock per week, every wrong answer classified by error type within 24 hours of attempt. Exit criterion: three consecutive QA sectionals at 38+ net score.
| Phase | Weeks | Hours/wk | Drill target | Primary topics |
|---|---|---|---|---|
| 1 — Arithmetic foundation | 1-3 | 12 | 60-80 Qs/wk | Ratios, %, P/L, SI/CI, Averages, TSD, TW |
| 2 — Algebra and Number Theory | 4-6 | 11 | 50-70 Qs/wk | Equations, Inequalities, Progressions, Functions, Divisibility |
| 3 — Geometry and Modern Math | 7-9 | 10 | 40-60 Qs/wk | Triangles, Circles, Coord, Mensuration, Logs, P&C |
| 4 — Mixed sectional grind | 10-12 | 12 | 3 sec + 1 mock/wk | All topics under timer |
The split intentionally drops total hours in Phase 3 — geometry rewards depth of recognition, which compounds faster from focused short sessions than from long grinding ones. Phase 4 climbs back up because the constraint becomes timer adaptation, not concept depth.
Section anchor: 4 phases, hours and exit criteria.
Question selection - 3-pass method inside 40 minutes
Takeaway: The right question order protects both time and accuracy.
Pass 1: solve direct familiar questions. Pass 2: return to medium questions with a clear setup. Pass 3: attempt stretch questions only if time remains. Mark any question with unclear entry after 60-75 seconds and move. A hard question is not expensive because it is hard; it is expensive because it prevents two solvable questions later.
Section anchor: 3 passes and 75-second first check.
TITA and MCQ decisions - no penalty does not mean no cost
Takeaway: TITA questions cost time even when they do not cost negative marks.
Use TITA attempts when the setup is clear. Do not spend 4 minutes on a no-penalty question that blocks two MCQs with high confidence. For MCQs, use options, bounds, and estimation when exact solving is long.
A useful TITA filter: attempt the TITA if you can name its answer-format before solving (integer, fraction, terminating decimal, two-digit number). If the answer-format is unclear from the question, the input-validation rules will compound the time cost — solve and re-solve, because TITA does not tell you when you are close. Save those for the third pass.
Section anchor: 4-minute cap on stubborn questions.
QA review - record the first wrong turn

Takeaway: The first wrong turn matters more than the final wrong answer.
After each mock, classify every lost QA mark into concept gap, setup error, calculation drift, or late exit. Then repair the top two categories during the next week. This keeps review measurable and prevents repeating the same chapter with no evidence of improvement.
| Error cause | Repair task | Proof |
|---|---|---|
| Concept gap | Redo concept set | 20 correct in a row |
| Setup error | Write equations only | 15 questions |
| Calculation drift | Unit and sign checks | 10 corrected errors |
| Late exit | Timer drill | 5 timed sets |
Section anchor: 4 QA error causes.
QA error categories and repair drills
Takeaway: Six error types cover almost every QA mark lost in mocks. Each one repairs through a different drill — generic re-practice is the wrong tool.
The four-cause table above is the minimum review surface. The six-category version below is what serious aspirants use after week 8, because it isolates the repair drill that actually moves the needle.
1. Calculation slip. You set up correctly, picked the right approach, and dropped a sign or a zero. Repair: 10-question speed-arithmetic drills, no concept content, only two-digit and three-digit operations under 8 seconds each.
2. Formula recall miss. You knew the topic but blanked on the identity (a quadratic identity, a P&C formula, a logarithm rule). Repair: build a 30-line formula card from your own mock errors, recall test daily, rebuild the card weekly.
3. Set-up error. You understood the question but chose the wrong representation (algebra where a ratio is faster, equations where a diagram is faster). Repair: solve 15 questions in setup-only mode — write the equation or draw the figure, do not compute the answer, score yourself on representation choice alone.
4. Time-greed error. You stayed in a question past the 90-second threshold because the answer felt close. Repair: a 22-question timed sectional with a hard 90-second-per-question external timer that audibly cuts you off.
5. Language misread. You solved a different question than the one asked (find the area, you returned the perimeter; find , you returned ). Repair: read every question aloud once before setup, underline the noun you are asked to return.
6. No-idea-where-to-start. You read, re-read, and still had no entry. This is a concept-gap masquerading as a setup-error. Repair: log the topic on a "no-entry list" and book a 45-minute targeted review with concept videos plus 10 isolated questions on that sub-topic.
The discipline that matters: every lost mark must land in one of these six buckets within 24 hours. Aspirants who do not log lose the diagnostic signal — and lose the same marks next mock.
Section anchor: 6 error categories with named drills.
FAQs
Which QA topics should I do first?
Start with arithmetic and algebra, then geometry and selected modern math. Use previous papers to adjust weight.
How many QA questions should I attempt?
Train to maximize net score. Attempt count should rise only when accuracy stays stable.
Is TITA always worth attempting?
No. No negative marking removes penalty risk, not time cost.
How important is Vedic math for CAT QA?
Useful for two-digit multiplication, squares, and percentage computation under time pressure. Not a substitute for topic recognition. If you have 12 weeks left, spend 2 hours on Vedic shortcuts in week 1 and stop — beyond that, the marginal return drops sharply and the time is better spent on topic drills.
Should I memorise formula sheets or derive on the fly?
Memorise the 30-40 identities you actually use — quadratic identities, AP/GP sums, common logarithm values, basic P&C formulas. Derive everything else when it appears. A formula you cannot recall in 5 seconds is a formula that will cost you a setup error in a mock. Build the card from your own mock errors, not from a coaching handbook.
How do I improve QA from 70 to 90 percentile in 60 days?
Three changes. First, audit your last two QA sectionals — most candidates in the 70-percentile band lose 8-12 marks to time-greed errors and calculation slips, not to concept gaps. Second, switch to the 8-24-8 minute budget and the 60-75 second skip rule. Third, drill the bottom-two error categories from the review ledger, not the top-two. The 70-to-90 jump is usually a discipline change, not a syllabus expansion.
How many TITA questions are worth chasing?
Roughly half. CAT QA carries 7-8 TITA questions per paper. A disciplined aspirant attempts the 4-5 with a clear answer-format and a one-sentence solution path, and treats the other 3-4 as pass-3 candidates. Attempting all TITAs because "they have no negative marking" is one of the more expensive habits in the section — the time cost is real even when the mark cost is not.
Conclusion
This week, complete 120 arithmetic and algebra questions, 2 mixed timed sets, and 1 mock QA review. Your proof of progress is a 6-cause error table, not a finished chapter list.
References
[1] Indian Institutes of Management, "CAT official website," 2025. [Online]. Available: https://iimcat.ac.in/. Accessed: Jun. 15, 2026.
[2] Cracku, "CAT Quant topic-wise weightage analysis," 2025. [Online]. Available: https://cracku.in/cat-quant-topic-wise-weightage/. Accessed: Jun. 15, 2026.
[3] 2IIM, "CAT previous-year question papers," 2025. [Online]. Available: https://online.2iim.com/CAT-question-paper/. Accessed: Jun. 15, 2026.
[4] 2IIM, "CAT score calculator and score-vs-percentile estimates," 2025. [Online]. Available: https://online.2iim.com/CAT-score-calculator/. Accessed: Jun. 15, 2026.
[5] Cracku, "CAT score calculator," 2025. [Online]. Available: https://cracku.in/cat-score-calculator/. Accessed: Jun. 15, 2026.
[6] Career Launcher, "CAT marks vs percentile," 2025. [Online]. Available: https://www.careerlauncher.com/cat-mba/cat-marks-vs-percentile/. Accessed: Jun. 15, 2026.
[7] InsideIIM, "CAT preparation and admission analysis," 2025. [Online]. Available: https://insideiim.com/. Accessed: Jun. 15, 2026.
[8] MBAUniverse, "CAT score vs percentile analysis," 2025. [Online]. Available: https://www.mbauniverse.com/articles/cat-score-vs-percentile. Accessed: Jun. 15, 2026.
[9] IMS India, "CAT analysis and preparation resources," 2025. [Online]. Available: https://www.imsindia.com/blog/cat/. Accessed: Jun. 15, 2026.
[10] Career Launcher, "CAT preparation resources," 2025. [Online]. Available: https://www.careerlauncher.com/cat-mba/. Accessed: Jun. 15, 2026.
[11] National Institutional Ranking Framework, Ministry of Education, "India Rankings 2025: Management," 2025. [Online]. Available: https://www.nirfindia.org/Rankings/2025/ManagementRanking.html. Accessed: Jun. 15, 2026.
[12] Cracku, "CAT exam pattern: question count, marking scheme, and section breakdown," 2025. [Online]. Available: https://cracku.in/cat-exam-pattern. Accessed: Jun. 15, 2026.
[13] Times of India Education, "CAT 2025 exam pattern and strategy reporting," 2025. [Online]. Available: https://timesofindia.indiatimes.com/education/news. Accessed: Jun. 15, 2026.
Related reading
CAT preparation with weak QA background: the 4-month bridge
Use a 4-month bridge: diagnose, rebuild school math, shift to CAT arithmetic, then add mocks.
CAT Percentile Explained for 2026
Understand CAT percentile as a rank-based measure, why it differs from marks, and why score tables must be treated as year-specific estimates.
The Complete CAT Mock Test Playbook for 2026
Use a 12-week CAT mock-test playbook with mock frequency, 48-hour postmortems, section repair, and score-table caveats.
CAT Normalisation Explained: The Equi-Percentile Idea
Explain CAT normalisation in plain English: why slots need scaling, how equi-percentile thinking works, and how raw score becomes percentile.